
Excel入門といえばVLOOKUPというくらい有名なVLOOKUP関数ですが、みなさんちゃんと使いこなしてますか?
今日は構造化参照というテクニックを使って、VLOOKUPを100万倍便利にする方法を紹介します。
VLOOKUPをこんな使い方しちゃってませんか?

メインの構造化参照について話す前に、もっと基本的な部分の話から始めます。
私の経験上、構造化参照とかいう以前に、意外と間違った使い方をしてしまっている人は多いはずです。
以前のエントリでも書いたOFFSETにも関連する話になります。

参照先に行を追加するたびに式を書き換えるのはNG
参照先の表に行が追加されるたびに、数式を書き換えているケースをよく見かけます。
多くの人が「列全体を指定すると検索範囲が尋常でない数になるので、処理が遅くなってしまうのではないか」と考えるようです。
ですが、実はそんなことをする必要はまったくありません。
そもそもの話として、VLOOKUPを含むほとんどの関数では列全体を選択しても処理速度はほとんど変化しないんです。
Web上では「検索範囲をOFFSETで動的に指定することで検索回数を減らすことができ処理が高速化する」などちゃんちゃらおかしいことを推奨しているページもあります。
しかし、まったくもってこれは無意味です。
Excelはほとんどの関数で最終行を自動認識して処理を行っています。
わざわざCOUNTAと揮発性関数のOFFSETを組み合わせたり、余計な処理を入れるのは今すぐやめましょう。
本当に本末転倒です。
では、どうすればいいのでしょうか?
行を追加していくなら列全体を参照しましょう
簡単です。
先ほども言いましたが、列全体で指定してください。
これ、ちょっとリテラシーがある人だと逆に避けようとしがちな行為だと思います。
最小限の範囲を指定した方が無駄がないという感覚は間違っていませんが、実行速度にほぼ差がないんですね。
したがって、表の末尾にレコードを単純に追加していくという運用なら、参照範囲を列全体として指定すれば元の数式を変更する必要はありません。
本当に実行速度に差が無いのか検証
5万行のデータを使って検証してみます。A列に1~50,000の連番をセットし、B列には1~100,000の範囲で乱数を発生させます。
B列をキーに昇順にソートしてA列をランダムに並べ替えて検証スタートしましょう。
以下の3パターンを比較してみます。
- 列全体を参照したVLOOKUP
- A1:B50000を参照したVLOOKUP
- OFFSETで動的に範囲指定したVLOOKUP
VBAのWorkSheetFunctionをそれぞれ10,000回ずつ実行したときの時間を計測して検証しましょう。
使用したコードは次のようなものです。
Sub MeasureVlookupCalcTime()
Dim startTime As Double
Dim i As Long, tmp As Variant
startTime = Timer
For i = 1 To 10000
tmp = WorksheetFunction.VLookup(i, Columns("A:B"), 2, False)
Next
Debug.Print "Case1: " & Timer - startTime
startTime = Timer
For i = 1 To 10000
tmp = WorksheetFunction.VLookup(i, Range("A1:B50000"), 2, False)
Next
Debug.Print "Case2: " & Timer - startTime
startTime = Timer
For i = 1 To 10000
tmp = WorksheetFunction.VLookup(i, Evaluate("OFFSET(A1:B1,0,0,COUNTA(A:A))"), 2, False)
Next
Debug.Print "Case3: " & Timer - startTime
End Sub計測結果が以下でした。
| 計測回数 | 列参照 | 範囲参照 | OFFSET参照 |
|---|---|---|---|
| 1 | 3.68 | 3.69 | 6.67 |
| 2 | 4.14 | 3.99 | 7.20 |
| 3 | 4.17 | 4.63 | 6.85 |
| 4 | 3.88 | 3.95 | 7.03 |
| 5 | 4.45 | 4.47 | 7.43 |
| Ave. | 4.07 | 4.15 | 7.03 |
誤差レベルですが、むしろ列参照のほうが速い結果になりました。
OFFSETは揮発性関数なだけあって2倍近く時間がかかっています。使う意味はまったくなさそうですね。
構造化参照は列でも拡張できる
ここまで、行が増えていくパターンは列全体を参照することでカンタンに解決可能なことが分かりました。
しかし、上記は「行」に限った話で、列の追加・削除・入替が発生する場合には依然として式の変更が必要になります。
VLOOKUPでどこから引っ張ってくるかを判断するのに、何列目かを画面上で数えたりした経験はありませんか?
元となる表の列数が多くなってくると、どのデータが何列目か分かりにくくなります。
少しかしこい人ならCOLMUN関数で何列目かを把握したりしているかもしれませんが、この方法でもまだ問題はあります。
列数を数字で指定することに無理がある
がんばってようやく見出した列番号(たとえば17だか)を入力したとしましょう。
せっかく見つけ出した列番号も、あとから表の列の順序を入れ替えたり、追加される列があったりするとイチから修正しなくてはいけません。
で、また数式とにらめっこするなんてことが平然と行われているのが多くのオフィスでの現状と思います。
さっきの17という数字がたとえば21などの他の数字に変わることになりますが、こういうのって手作業でやってる限り、ちゃんと修正したつもりでも漏れがあったりしてデータがぐちゃぐちゃになるんですよね
構造化参照なら位置ではなくラベルで指定するのでズレない
いよいよ本題ですが、これまで述べてきたような問題を構造化参照なら一発で解消できます。
ちょっと難しい言葉で言い表すなら、「数式の可読性と保守性が格段に向上する」といった感じです。
「構造化参照」という言葉自体を聞いたことがない人がほとんどだと思いますので、まずは使い方から説明しましょう。
構造化参照にはテーブル機能を使う
構造化参照を利用するには、検索範囲をまずテーブル化する必要があります。
ピボットテーブルを使ったことはあっても、テーブル機能をしっかり利用している人は少ないかもしれませんね
なぜテーブルにする必要があるかというと、データが「構造化」されるからです。
Excelではテーブルを作成すると、それまでは個別だったセルがテーブルというひとつのまとまりとして認識されます。
そして、そのテーブルというまとまりの中で、データ部、ラベル部、各列などがさらに小さなまとまりとして区分されることになります。これが構造化です。
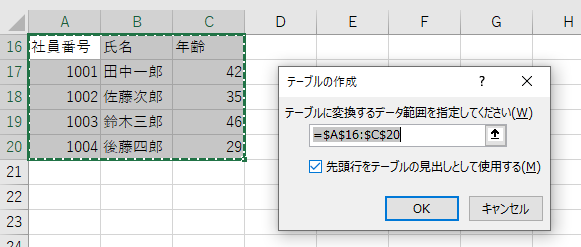
構造化されたデータはブロックごとに取り出せる
セル範囲をテーブルに変換すると、そのテーブルには「テーブル1」のような固有の名前が与えられます(この名前はユーザーが任意に変更することも可能)。
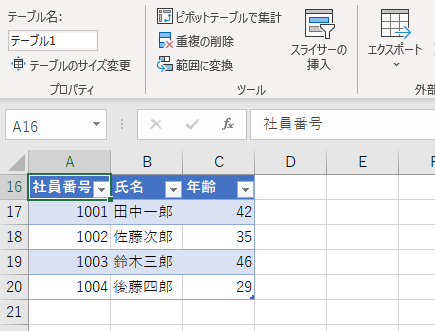
こうしておくと、これまではセル番地を直接指定していたところを、「テーブル1」の「社員番号」列というように、表の名前とラベル名で指定することができるようになります。
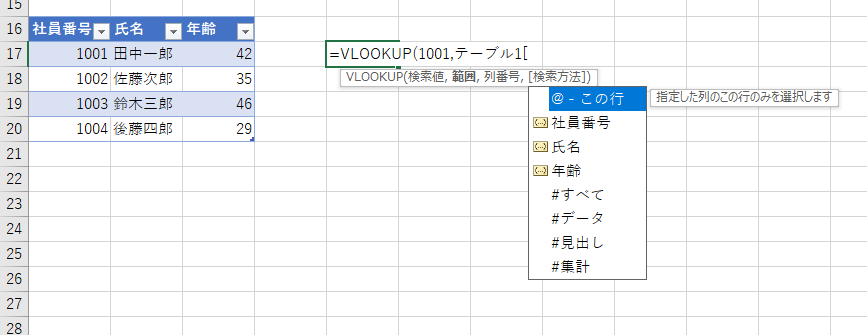
データの選択は、以下のようにテーブル名に続いて、構造化要素を[]で囲んで指定します。
テーブル名[列の名前]
これにより、テーブル上で列の順番が入れ替わろうが、行が追加されようが、「テーブル1」の「社員番号」列が常に参照されるようになります。
式の中に名前が直接出てくるから、なにより読みやすいし、変更にも強くなります。
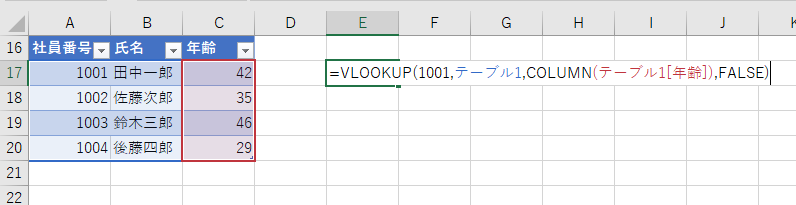
構造化参照による読みやすさアップ
構造化参照を使うならテーブル名やラベル名はしっかり付けていくのが大前提です。
たとえば、以下の2つの式ならどちらがわかりやすいでしょうか?
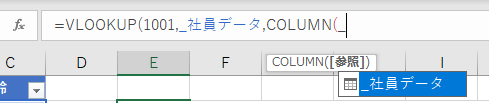
=VLOOKUP(1001,テーブル1,COLUMN(テーブル1[列3]),FALSE)」
=VLOOKUP(1001,社員データ,COLUMN(社員データ[年齢]),FALSE)」
2番目の式のほうが何をやっているか圧倒的にわかりやすいですよね
ちなみに構造化参照していない状態では、以下のような式なので1番目の式よりさらに分かりにくいです。
=VLOOKUP(1001,$A$16:$C$20,3,FALSE)」
このレベルになると自分が作ったファイルでさえ、後から見ると意味不明になるので本当に非効率的です。
構造化参照を使わないと、後から見ても$A$16:$C$20がなんの表なのかもわかりませんし、列数が3が何の列かもわかりません。
だから、他の人へファイルを引き継いでもまずは解読しないと仕事にならない、なんてことがまかり通っているわけです。
構造化参照を利用することで、可読性が向上するし、参照する表や列数を間違えたりするリスクがぐっと減ります。
なぜマイクロソフトはこんなに便利な機能を目立たないところに配置しているのか不思議なレベルです。
[ホーム]タブの右半分ぜんぶテーブルにするくらいして世の中に広めて欲しいものですね。
テーブル名をつける際のポイント
構造化参照はいま説明した内容だけでも十分便利なんですが、ちょっと面倒なところがあります。
数式にテーブル名を入力するために途中で半角と全角を切り替えるの死ぬほどダルくないですか?
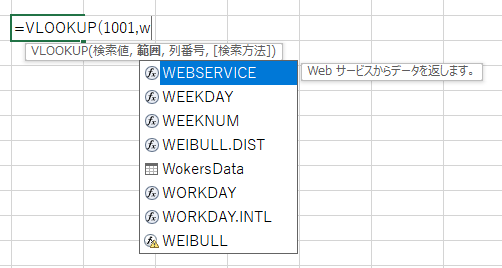
この問題を解決するために、テーブル名の先頭にアンダーバー(_)をつけることを激しくオススメします。
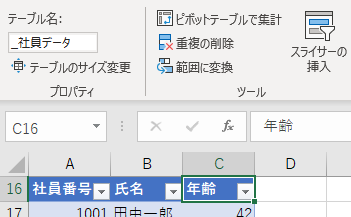
これをやるだけで全角半角の切り替えも不要になりますし、ひと目でテーブルだと分かるようになります。
ちょっと詳しい人だと「名前の定義」も使ってたりするので、全角文字列だったとしても、単なる名前付きのセル範囲かテーブルなのかの区別が付かなかったりするんですよね。
なので、「アンダーバー+全角文字列」がもっともオススメする運用です。
同じ理由で、英数字だけのテーブル名よりこの運用をオススメします。
半角全角の切り替え不要というだけなら、英数字だけにすればOKなんですが、関数と混じってくるのがダルいです。
さらなる自由のためにVLOOKUPよりINDEX+MATCHを
ここまで説明したことを実践するだけでも、全サラリーマンの上位1%に入ることはほぼ間違いありませんが、これでもなお解消されない問題もあります。
たとえば、COLUMN関数を使って列を指定したとしても、VLOOKUP参照先のテーブルがA列から配置されていないとCOLMUN関数の値がずれてしまうという問題です。
ほかには、検索語句は常にA列になければいけないというVLOOKUP最大の欠点もあります。
テーブルの位置がB列に移動したらCOLMUNに-1を足す必要がありますし、社員番号ではなく氏名で検索したくなったら、1番左の列に氏名を持っていってあげる必要があります。
そもそも、VLOOKUPとかいう関数が使いにくいのでは?
そうなんです。VLOOKUPなんて使うのをやめましょう。
VLOOKUPじゃなくてもVLOOKUPと同じことが出来るどころか、むしろ不便が解消できます。それがかの有名なINDEX+MATCHという方法です。
ちょっとExcelに詳しい人なら聞いたことあるという人もいるかもしれません。
INDEX+MATCHの使い方
INDEX+MATCHはVLOOKUPの代用手段として有名ではありますが、INDEX関数もMATCH関数も、使ったことがない人はそれぞれがどういう関数かも知らないことが多いと思います。
- INDEX:ある配列の行番号と列番号を指定すると該当する配列要素を返す
- MATCH:1次元配列の要素を指定すると要素のインデックスを返す
『いったいどういうことだってばよ?!』
となる方もいると思いますが、詳しく書くと長くなるので今回は使い方に絞って説明します。
結論からいきましょう。実際の式を書くのでそのまま使ってください。
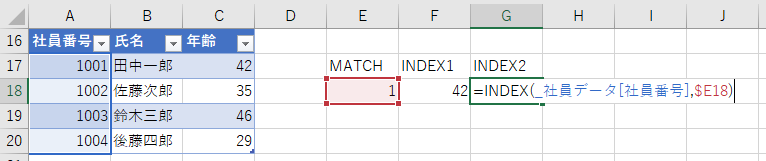
=INDEX(_社員データ[年齢],MATCH("田中一郎",_社員データ[氏名]),0))

カンタンに言うと以下のような構造になっています。
- MATCH:何行目にあるかを求める
- INDEX:MATCHで求めた行数のデータを取り出す
VLOOKUPで記述した式と比較すると、INDEX+MATCHではテーブルの位置によらない式になっていることがわかります。
また、検索項目だけでなく、検索キーもラベルで表示されているので、可読性がさらに向上しています。
構造化参照を利用することで、各ラベルは数式入力時にサジェスト入力されるので、いちいち元の表を見て該当列を探すといった作業もなくなり、仕事の効率も大幅に向上すること間違いなしです。
さらなる上級者を目指すには
INDEX+MATCHでは、何行目かを求めるMATCHと、その行数のデータを取り出すINDEXが別々に分かれています。
逆に言うと、VLOOKUPだとその2つを分けることができないんですね
実際の業務のケースを考えると、大抵の場合、VLOOKUPで引っ張ってくるデータは複数列になると思います。
つまり、何行目かを求める作業をExcelに重複して何回もやらせることになります。
無駄な作業をやらせると、当然Excelの動作は重くなります。
INDEX+MATCHを使う場合は、これらを分離して書くことで、行数を求める作業を1回だけで済ませることが可能です。
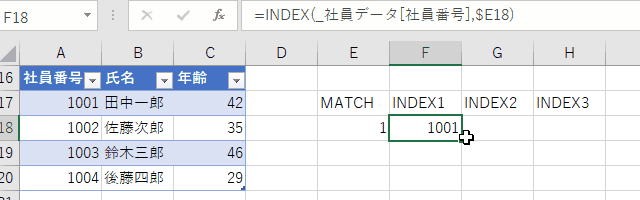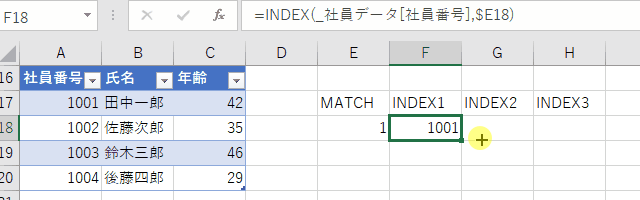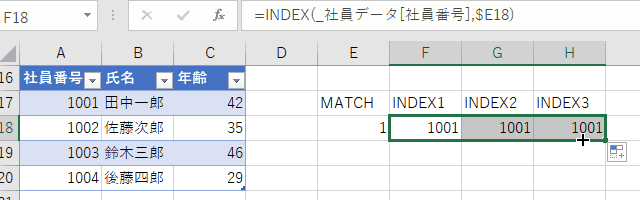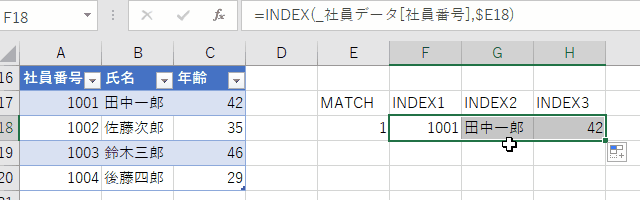
具体的には、MATCH項を作業セルに入力するのが良いでしょう。
この書き方だと、フィルハンドルを横方向に引っ張ると順番にデータが取り出せるのもVLOOKUPにはない利点です。
VLOOKUPを100万倍便利に使う方法まとめ
最終的にVLOOKUPではなくなってますが、得られる結果は一緒です。
真の目的は、より効率的にExcelを使うことですからまったく問題ありません。
【結論】
VLOOKUPを使わずに、INDEX+MATCHと構造化参照を使いましょう
VLOOKUPはこれで終わりじゃない
実はVLOOKUPには今回紹介したこととは別に、非常に重要な事実があります。
作業効率を良くするのに役に立つこと間違いありませんので、ぜひ楽しみに次の投稿をお待ちいただければと思います。


コメント